Motivation
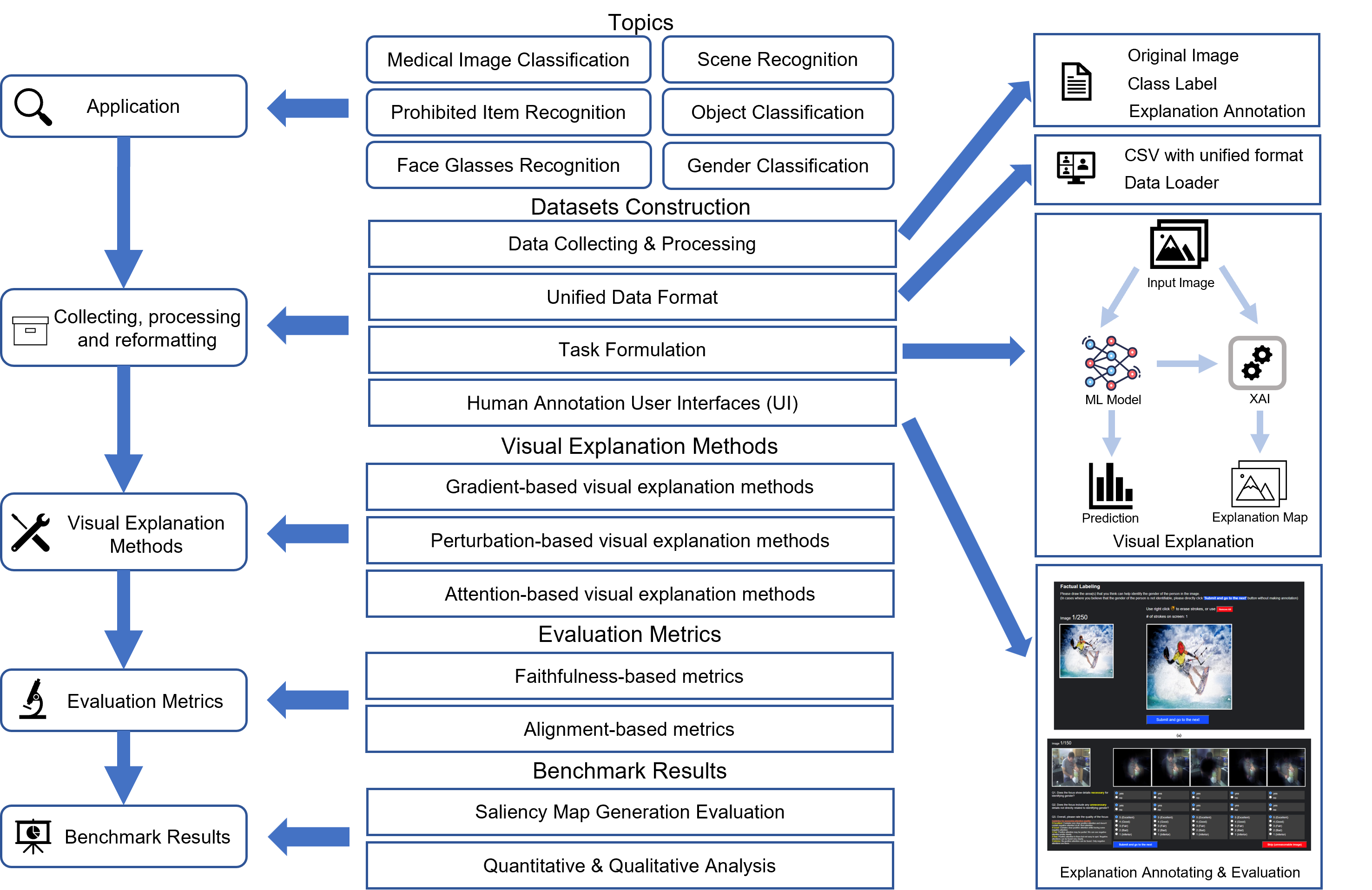
Explainable AI (XAI) has gained significant attention for providing insights into the decision-making processes of deep learning models, particularly for image classification tasks through visual explanations visualized by saliency maps. Despite their success, challenges remain due to the lack of annotated datasets and standardized evaluation pipelines. In this paper, we introduce Saliency-Bench, a novel benchmark suite designed to evaluate visual explanations generated by saliency methods across multiple datasets. We curated, constructed, and annotated eight datasets, each covering diverse tasks such as scene classification, cancer diagnosis, object classification, and action classification, with corresponding ground-truth explanations. The benchmark includes a standardized and unified evaluation pipeline for assessing faithfulness and alignment of the visual explanation, providing a holistic visual explanation performance assessment. We benchmark these eight datasets with widely used saliency methods on different image classifier architec- tures to evaluate explanation quality. Additionally, we developed an easy-to-use API for automating the evaluation pipeline, from data accessing, and data loading, to result evaluation.

Citation
Please consider cite us:
Zhang, Yifei, et al. “Saliency-Bench: A Comprehensive Benchmark for Evaluating Visual Explanations.” arXiv preprint arXiv:2310.08537.
BibTex:
@misc{zhang2025saliencybenchcomprehensivebenchmarkevaluating,
title={Saliency-Bench: A Comprehensive Benchmark for Evaluating Visual Explanations},
author={Yifei Zhang and James Song and Siyi Gu and Tianxu Jiang and Bo Pan and Guangji Bai and Liang Zhao},
year={2025},
eprint={2310.08537},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2310.08537},
}